
We present a technique for segmenting real and AI-generated images using latent diffusion models (LDMs) trained on internet-scale datasets. First, we show that the latent space of LDMs (z-space) is a better input representation compared to other feature representations like RGB images or CLIP encodings for text-based image segmentation. By training the segmentation models on the latent z-space, which creates a compressed representation across several domains like different forms of art, cartoons, illustrations, and photographs, we are also able to bridge the domain gap between real and AI-generated images. We show that the internal features of LDMs contain rich semantic information and present a technique in the form of LD-ZNet to further boost the performance of text-based segmentation. Overall, we show up to 6% improvement over standard baselines for text-to-image segmentation on natural images. For AI-generated imagery, we show close to 20% improvement compared to state-of-the-art techniques.
Teaching networks to accurately find the boundaries of objects is hard and at the same time annotation of boundaries at internet scale is impractical. Also, most self-supervised or weakly supervised problems do not incentivize learning boundaries. For example, training on classification or captioning allows models to learn the most discriminative parts of the image without focusing on boundaries. Our insight is that Latent Diffusion Models (LDMs), which can be trained without object level supervision at internet scale, must attend to object boundaries, and so we hypothesize that they can learn features which would be useful for text-based image segmentation.
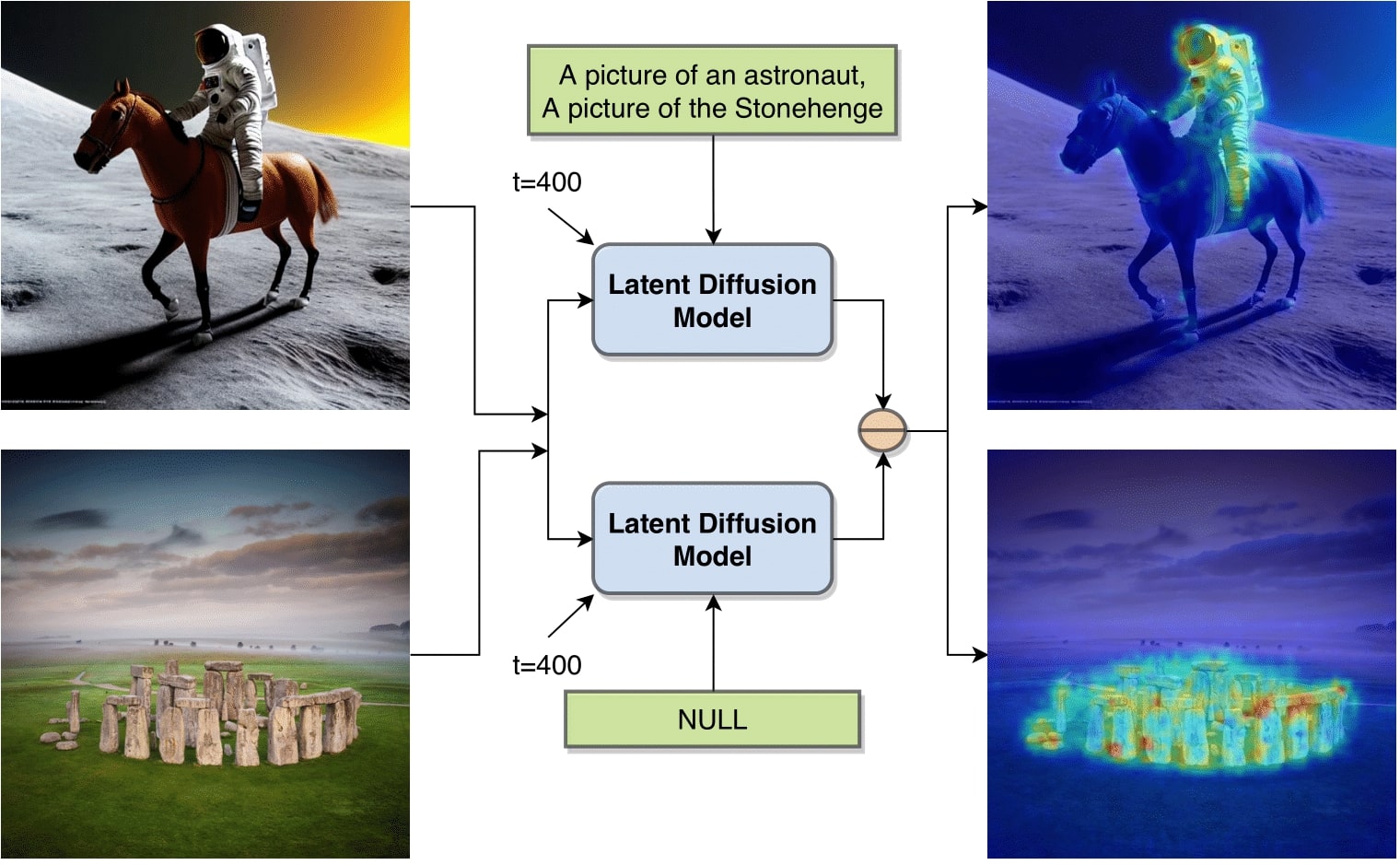
To test the aforementioned hypothesis about the presence of object-level semantic information inside a pretrained LDM, we conduct a simple experiment. We compute the pixel-wise norm between the unconditional and text-conditional noise estimates from a pretrained LDM as part of the reverse diffusion process. This computation identifies the spatial locations that need to be modified for the noised input to align better with the corresponding text condition. Hence, the magnitude of the pixel-wise norm depicts regions that identify the text prompt. As shown in the Figure 1, the pixel-wise norm represents a coarse segmentation of the subject although the LDM is not trained on this task. This clearly demonstrates that these large scale LDMs can not only generate visually pleasing images, but their internal representations encode fine-grained semantic information, that can be useful for tasks like segmentation.
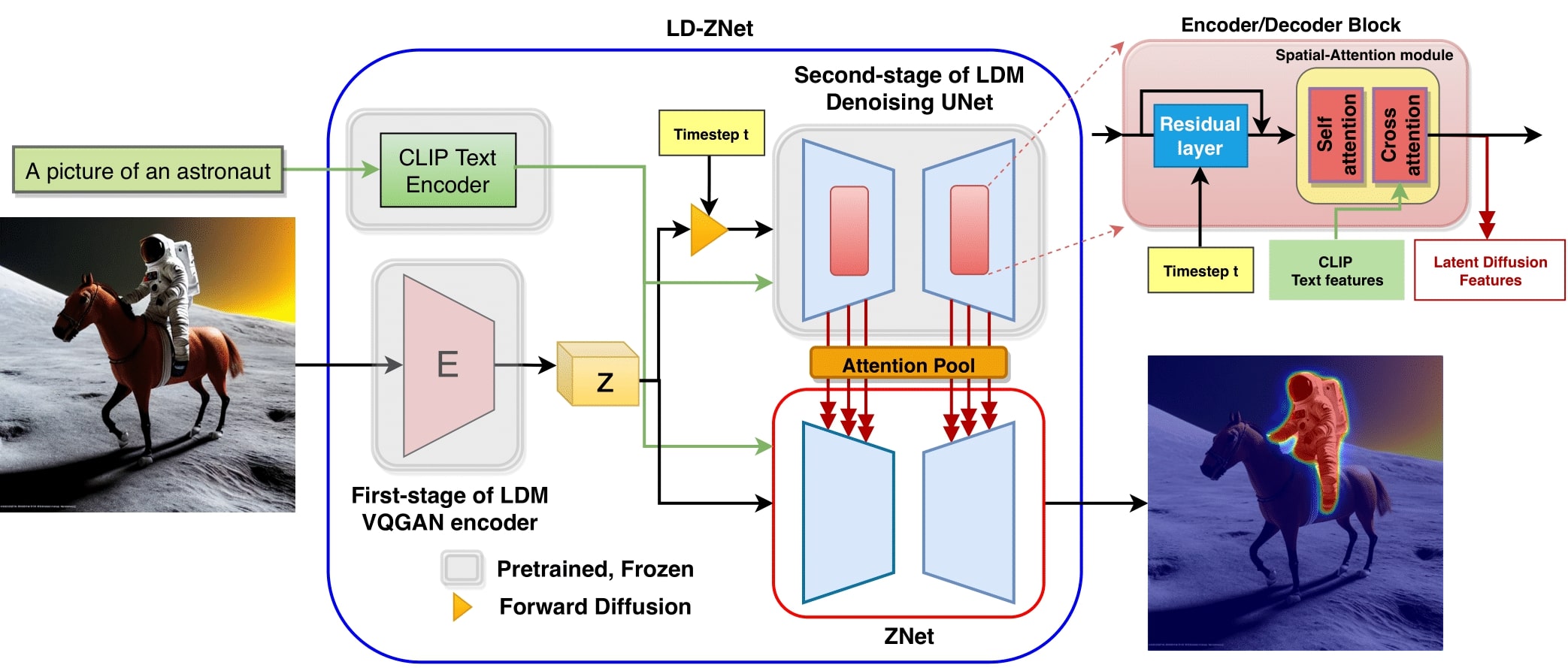
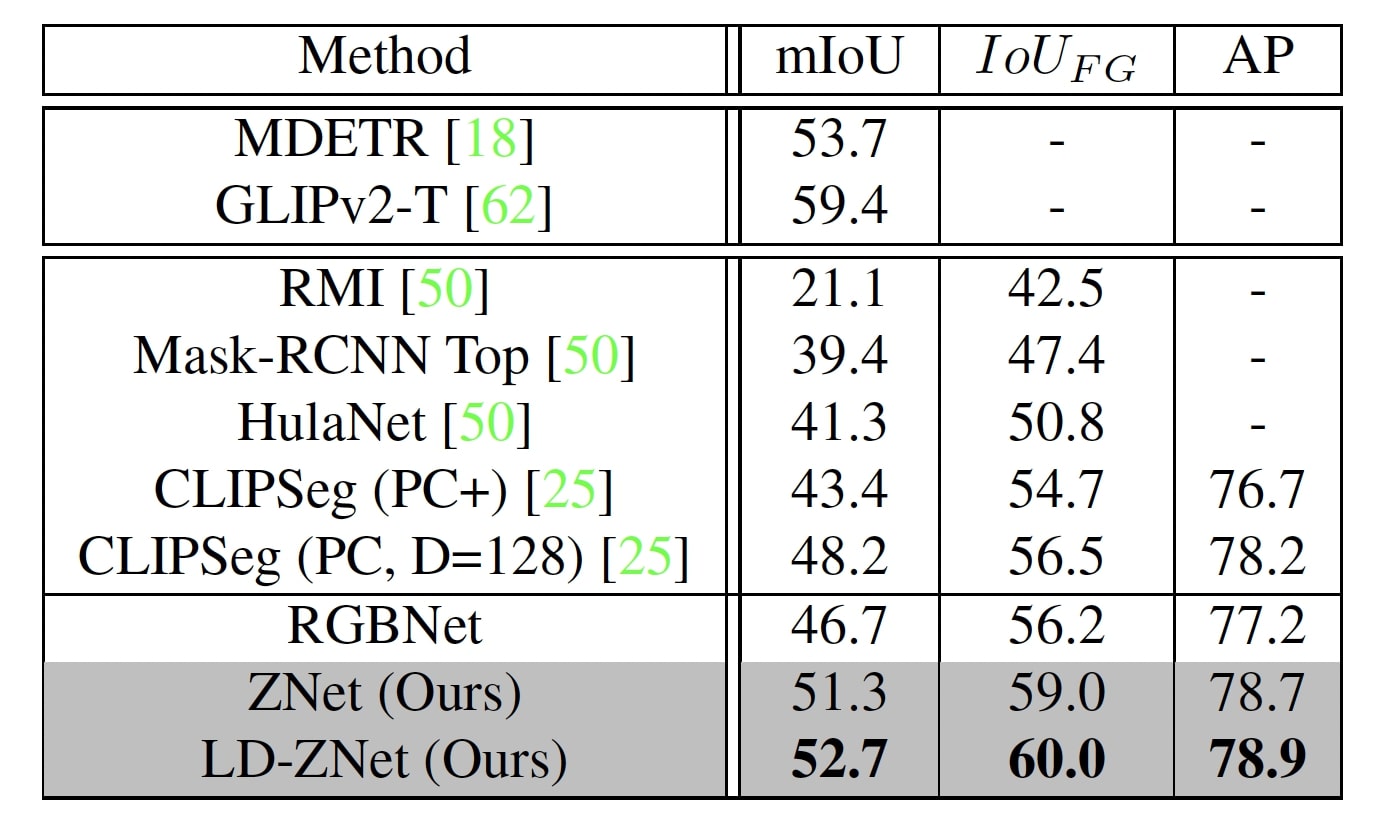
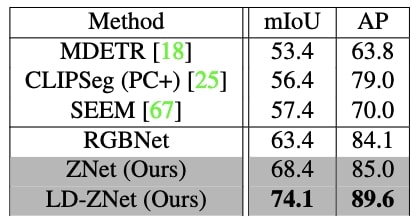
When tested on the Phrasecut dataset, we see a gradual improvement going from RGBNet->ZNet->LD-ZNet indicating the importance of both z-space of image as well as the amount of semantic information stored in the internal representations of the LDM. It can also be observed from the visual comparison on the right that LD-ZNet does well in segmenting the "hanging clock" and the "castle" better than RGBNet and ZNet.
Next, we were mainly focused on understanding the generalization of text-based segmentation methods on AI-images because of the traction the AI-generated content gained in the past couple of years. Moreover, several editing workflows such as inpainting require precise segmentation of objects in the image. Thus it becomes important to understand the generalization ability of the computer vision systems to AI-content. Hence we create an AI-generated dataset named AIGI that contains 100 AI-generated images gathered from the lexica.art website and 214 object instances labeled along with their categorical captions as shown below. We also make this dataset public for future research in this direction.




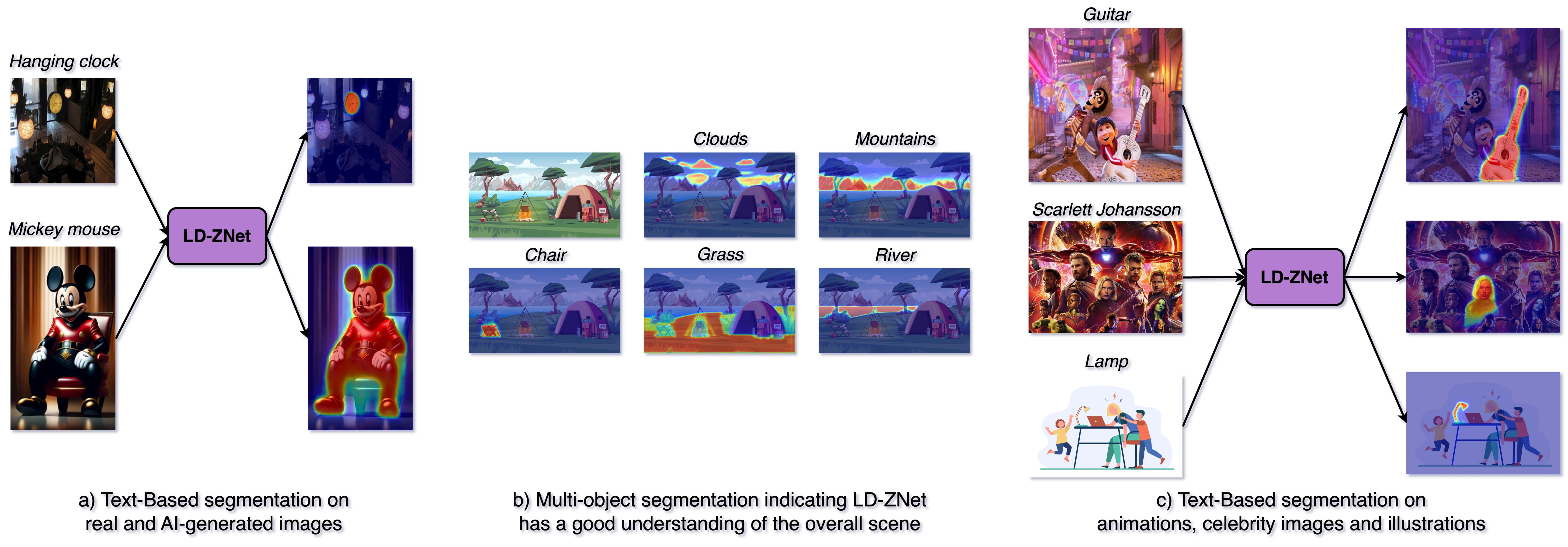
More qualitative examples where RGBNet fails to localize {``Guitar", ``Panda"} from animation images (top two rows), objects such as {``Lamp", ``Trees"} from illustrations (middle two rows) and famous celebrities {``Scarlett Johansson", ``Kate Middleton"} (bottom two rows). LD-ZNet benefits from using z combined with the internal LDM features to correctly segment these text prompts.

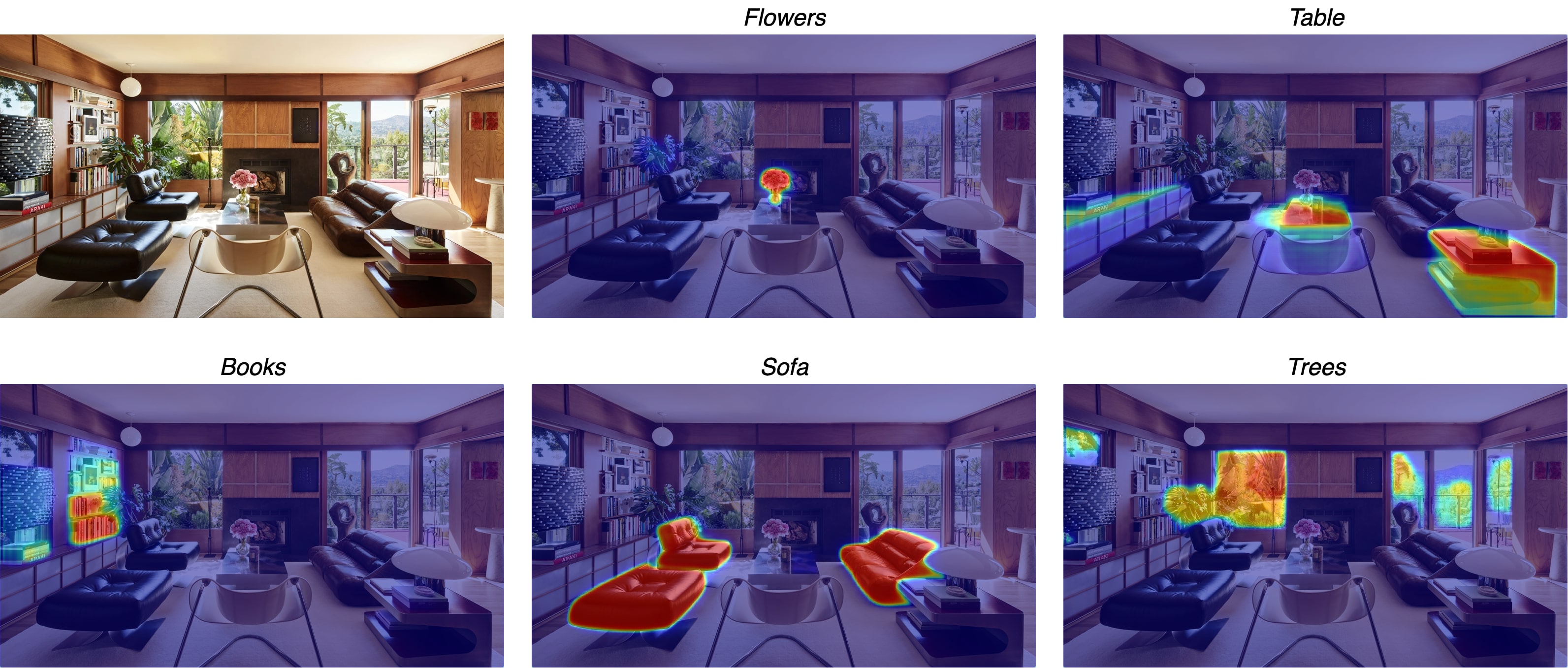
Multi-object segmentation on real and illustration images for various thing and stuff classes suggests LD-ZNet has a good understanding of the overall scene.
@InProceedings{PNVR_2023_ICCV,
author = {PNVR, Koutilya and Singh, Bharat and Ghosh, Pallabi and Siddiquie, Behjat and Jacobs, David},
title = {LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {4157-4168}
}